OCR
该应用程序利用 (OCR) 技术从图像中无缝提取文本, 尤其是书本封面和书脊. 通过采用先进的神经网络, 该应用程序可以有效地检测图像中的文本并准确识别它. OCR的处理包括2个必要步骤: 文本检测和文本识别. 文本检测模型直接在相机上运行, 快速识别图像中的文本区域. 当被检测到时, 文本区域将被传递给文本识别模型, 这将会被在主机系统处理. 该模型破译文本, 将其转换为机器可读的格式.
OCR的处理包括2个必要步骤: 文本检测和文本识别. 文本检测模型直接在相机上运行, 快速识别图像中的文本区域. 当被检测到时, 文本区域将被传递给文本识别模型, 这将会被在主机系统处理. 该模型破译文本, 将其转换为机器可读的格式.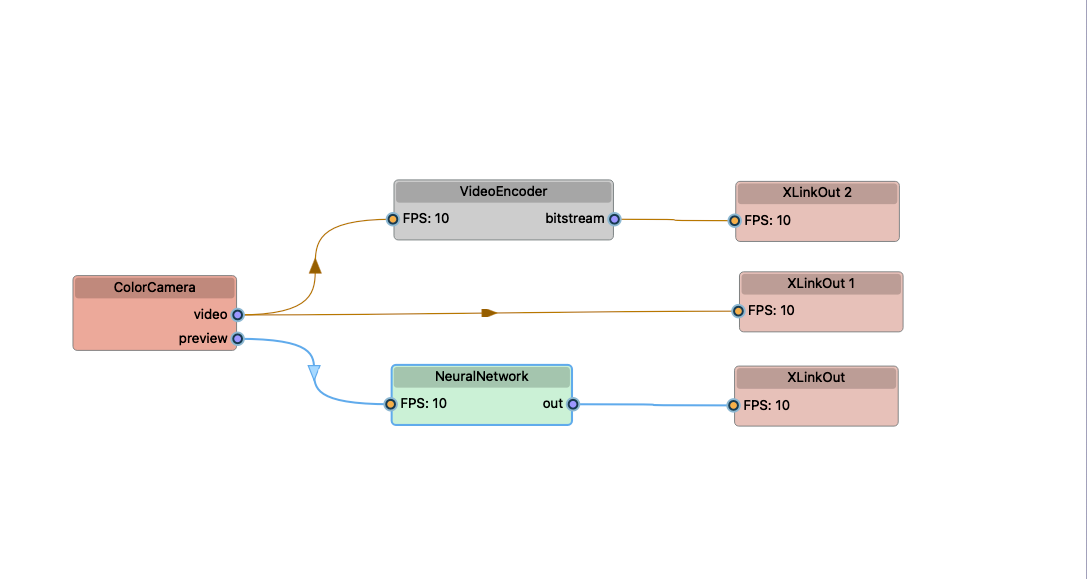 该应用程序提供 Open Library 的集成. 它根据识别的文本进行搜索, 检索有关已识别书籍的信息.该应用程序具有用户友好的前端界面. 用户可以使用设备的相机轻松捕捉书籍封面或书脊的图像. 然后应用程序会及时处理这些图像, 在前端以清晰、有组织的方式呈现提取的文本.
该应用程序提供 Open Library 的集成. 它根据识别的文本进行搜索, 检索有关已识别书籍的信息.该应用程序具有用户友好的前端界面. 用户可以使用设备的相机轻松捕捉书籍封面或书脊的图像. 然后应用程序会及时处理这些图像, 在前端以清晰、有组织的方式呈现提取的文本.View source code
