模型转换
总览
为了在我们的设备上充分使用HubAI的潜力, 它们需要被转换为它们要运行平台的 RVC 编译格式. 下面, 我们简单地分布说明, 指导使用我们的云服务在 HubAI 上进行转换. 对于本地 (离线) 模型, 请参考 Modelconverter 工具.转换指南
这里假设用于转换的模型已经被上传到了 HubAI. 如果此步骤还未完成, 请参考 模型上传 指南.
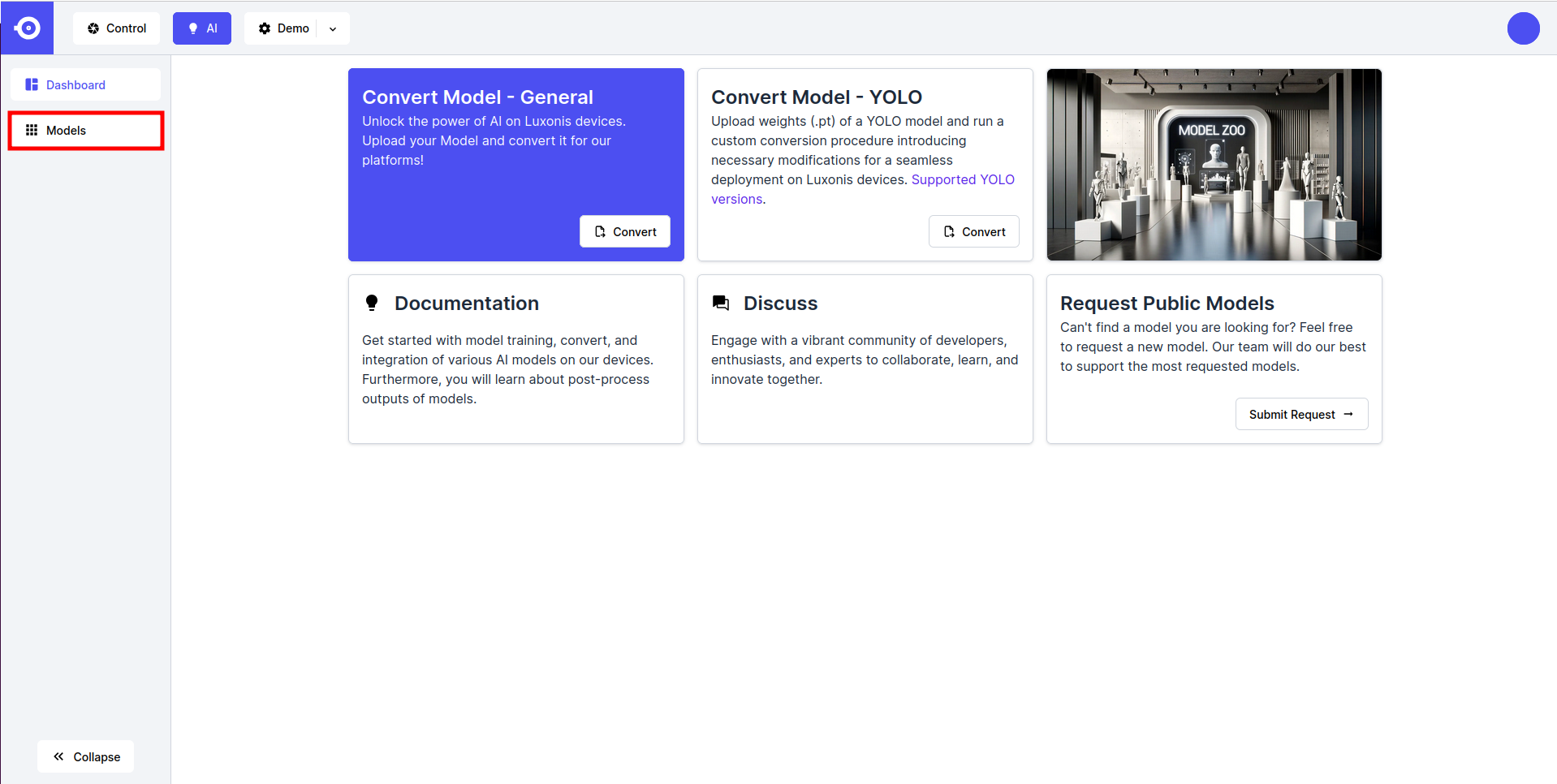
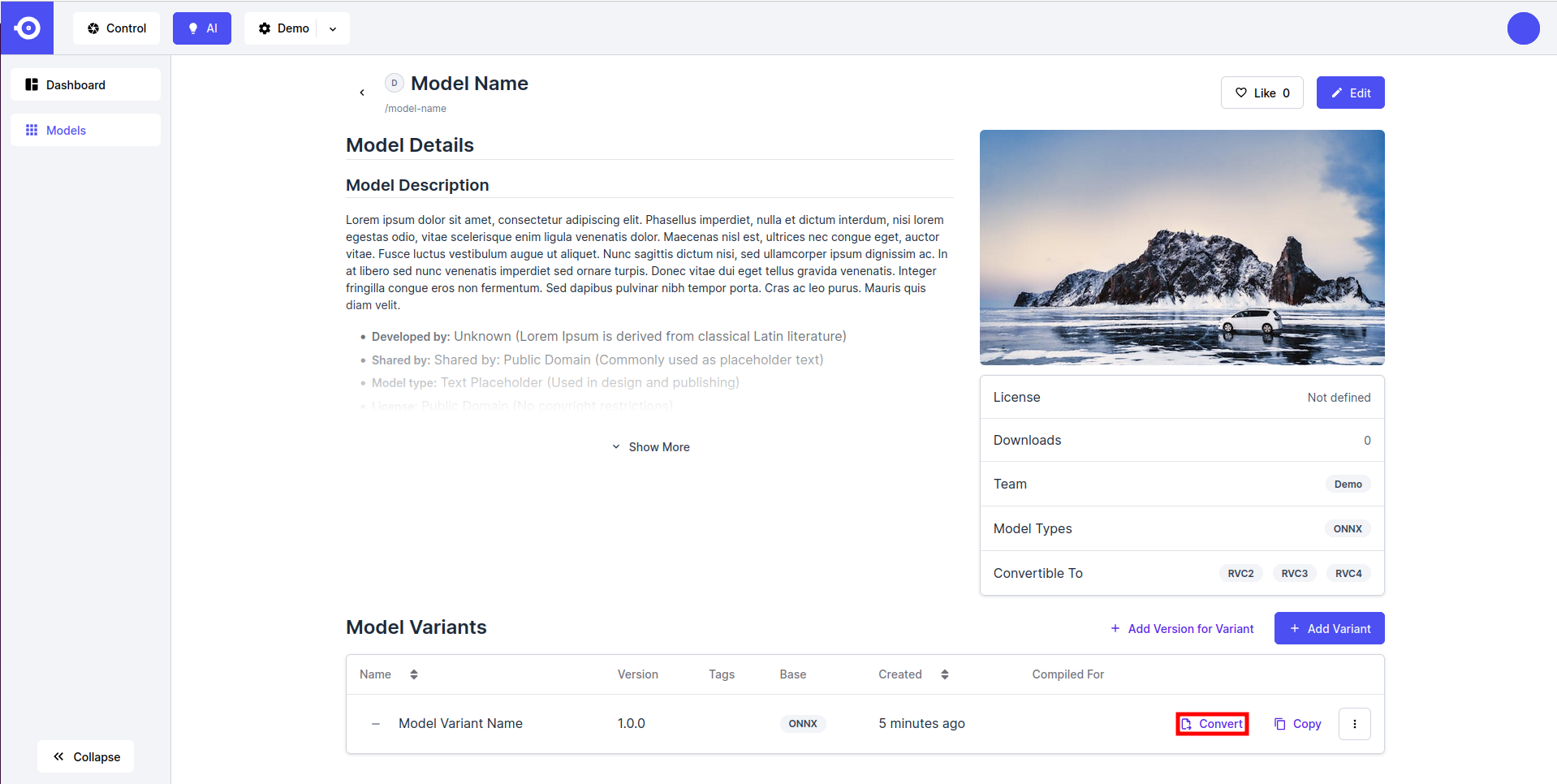
- 点击所需模型 (公有或私有)的图标, 下滑至 Model Variants 板块, 然后点击感兴趣的变体旁边的 Convert 按钮.
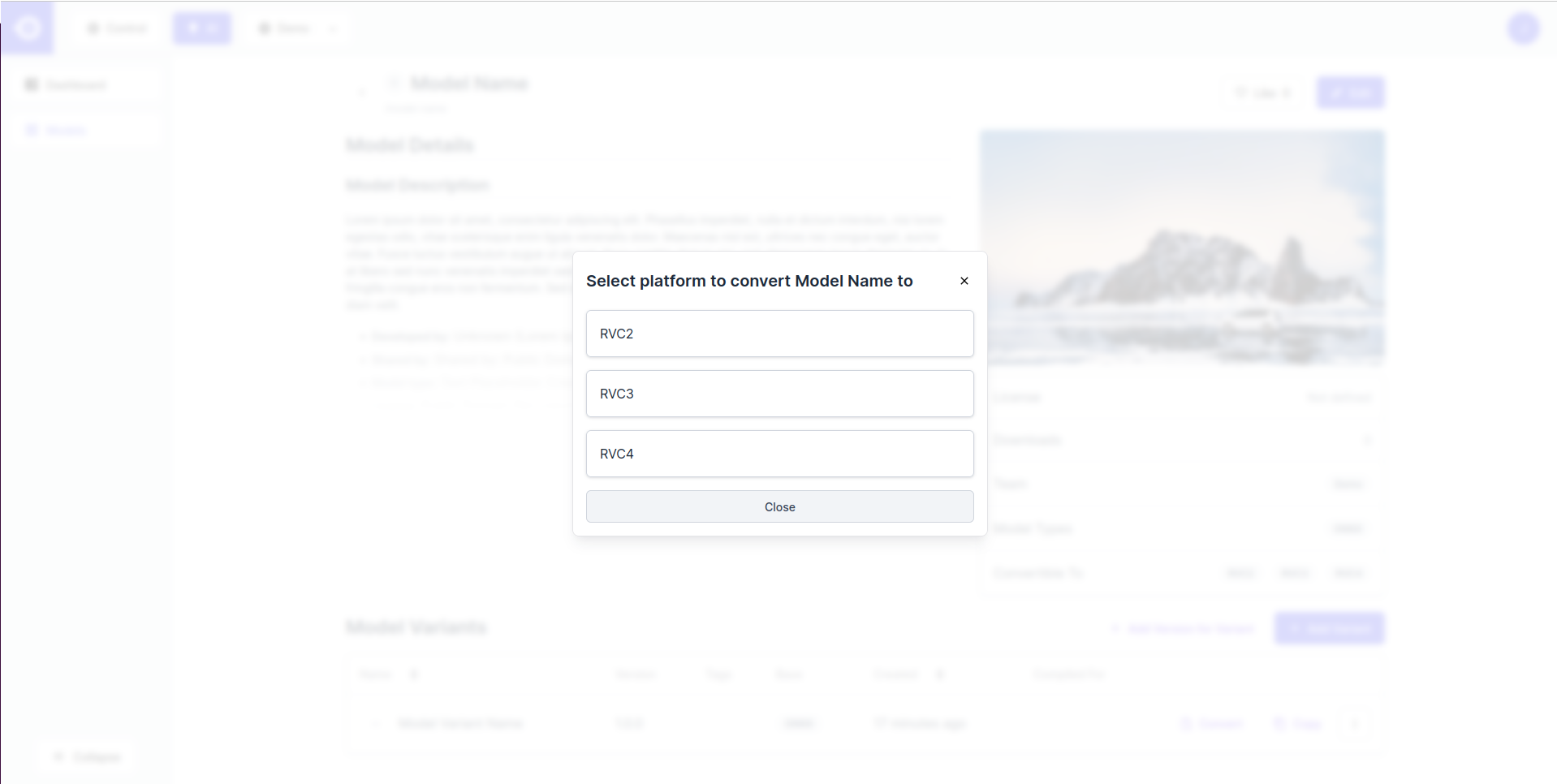
- 这会打开一个弹窗, 列出了可以转换模型的所有的 (RVC) 平台. 选择感兴趣的平台. 请注意, 这些选项取决于上传的模型文件的格式. 简单地说, 只有 ONNX 格式允许所有支持的平台的转换.
- 接下来, 系统会要求您填写模型的描述符和转换参数 (如果模型文件是NN存档, 则可能会预定义一些参数). 根据所选平台, 系统会要求您:
- Model Instance Name: 在 HubAI 上转换的模型的名称(e.g. RVC2).
- Ir version / Snpe version: 模型转换的目标格式版本.
- Disable Onnx Simplification (OPTIONAL): 选择此选项可在转换期间禁用ONNX模型简化(用其常量输出替换冗余运算符).
- Mo Args (OPTIONAL): 对于RVC2和RVC3(停止供应), OpenVINO Model Optimizer 用于将模型转换为IR格式. 您可以在此处指定自定义参数. 如果自定义参数和默认参数之间发生冲突, 自定义参数会始终保持优先. 请查阅 official documentation 以了解更多信息.
- Compile Tool Args (OPTIONAL): 对于RVC2, OpenVINO compile tool 被用于编译模型进行推理. 您可以在此处指定自定义参数. 如果自定义参数和默认参数之间发生冲突, 自定义参数会始终保持优先. 请查阅 official documentation 获取更多信息.
- POT Target Device: POT的目标设备 (仅RVC3). 最好设置为VPU, 如果失败则设置为ANY.
- Shape: 网络的输入形状.
- Scale Values: 用于每个通道的刻度值列表 (例如 123.675, 116.28, 和 103.53 用于 ImageNet).
- Mean Values: 用于每个通道的平均值列表 (例如 58.395, 57.12, 和 57.375 用于 ImageNet).
- Encoding From / Encoding To: 转换所需的输入通道顺序 (例如从 RGB 到 BGR 或 vice versa). Encoding From 定义基础模型的输入通道顺序, Encoding To 定义转换模型的所需顺序. 如果为两者传递相同的顺序, 则模型被转换, 而无需修改任何输入通道顺序.
- Quantization Data: 对于RVC3和RVC4平台的转换, 执行量化以降低模型计算和内存成本 (在转换概念部分阅读更多内容 Conversion Concepts ). 这个过程需要将示例输入数据传递给模型. 目前没有上传自定义量化数据集的选项, 但�我们提供了一些通用数据集供您选择 (从 Open Images V7 和 forklift-1 数据集中提取的1024张图像的精选集). 为获得最佳量化结果, 选择与模型的训练数据集最相似的一个 (或使用允许指定自定义量化数据集的 Modelconverter 工具切换到局部转换):
- Driving - 街道和车辆的图像 (OIv7 类 例如车辆, 小汽车, 交通灯等等);
- Food - 水果, 蔬菜, 生食和预制食品的图像 (OIv7 类例如苹果, 沙拉, 披萨等等);
- General - OIv7 图像的随机子集, 表示一组不同的对象和场景;
- Indoors - 室内空间的图像 (OIv7 类例如桌子, 椅子, 壁炉等等);
- Random - 随机像素图像;
- Warehouse - 仓库内部图像 (叉车-1 图像的随机子集);
- Max Quantization Images: 量化中使用的最大的图像数.
- Target Precision: 量化的目标精度 (仅限RVC4). 有两个选项可用: FP16 (半精度浮点量化) 和 INT8 (整形量化). 如果您需要在速度和准确性之间取得平衡, 同时将量化效果降至最低, 请选择FP16, 如果您想要获得最佳性能和模型压缩, 并且可以接受潜在的次要精度权衡, 请选择INT8.
在转换过程中, 预处理被嵌入到模型结构中. 通常建议填写相关参数 (Scale Values, Mean Values, and Encoding) 以便转换后的模型期望BGR输入, 而无需任何额外的尺度或均值偏移.预处理操作的顺序为:
- 反转输入通道;
- 减去均值;
- 按比例值除法.
- 填写完参数后, 点击 Export 按钮. 这将通过创建新的模型变型实例�并将其状态标记设置为 Pending 来启动转换过程. 转换过程将需要几分钟才能完成, 具体取决于模型的大小和复杂性.
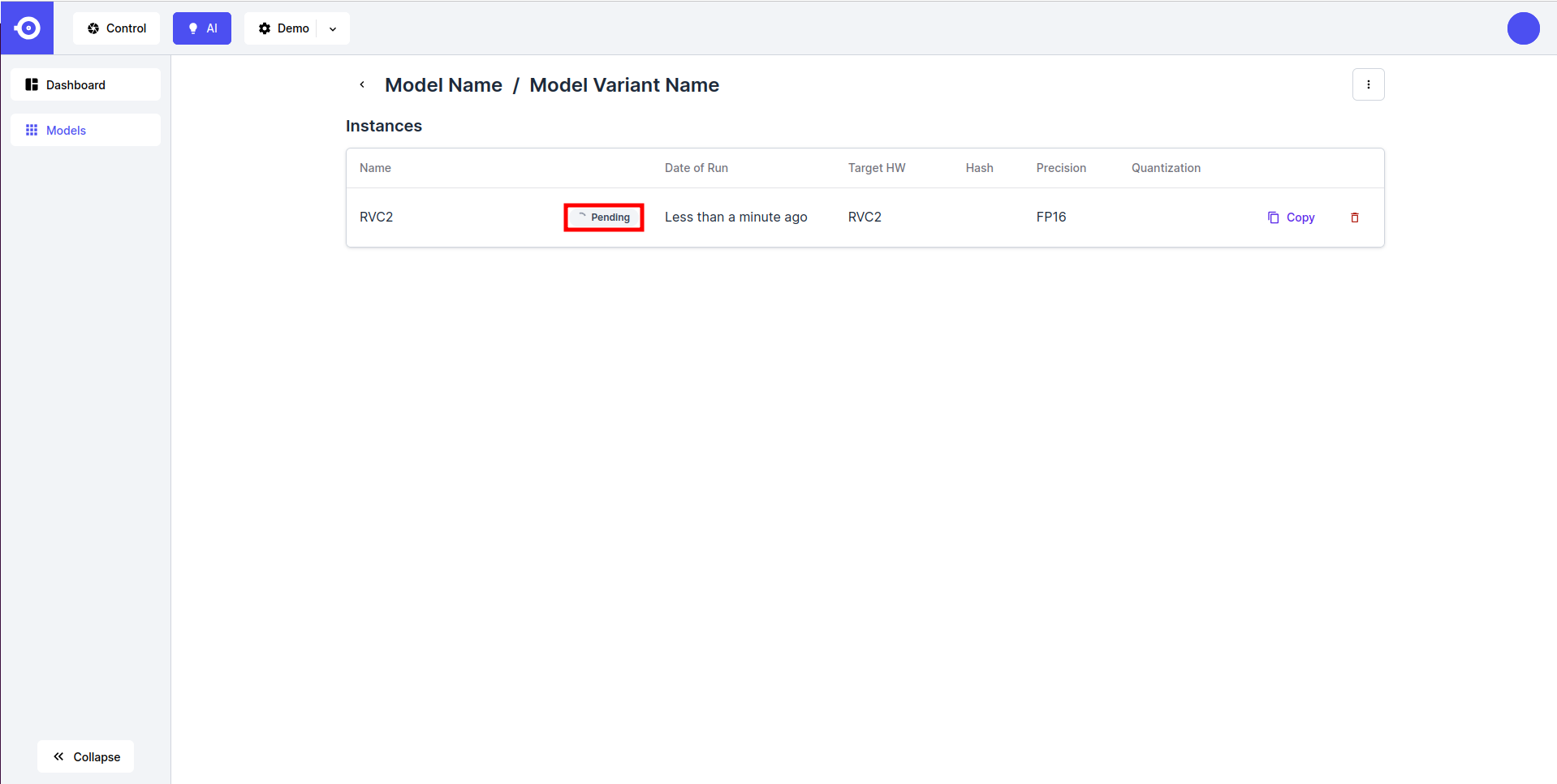
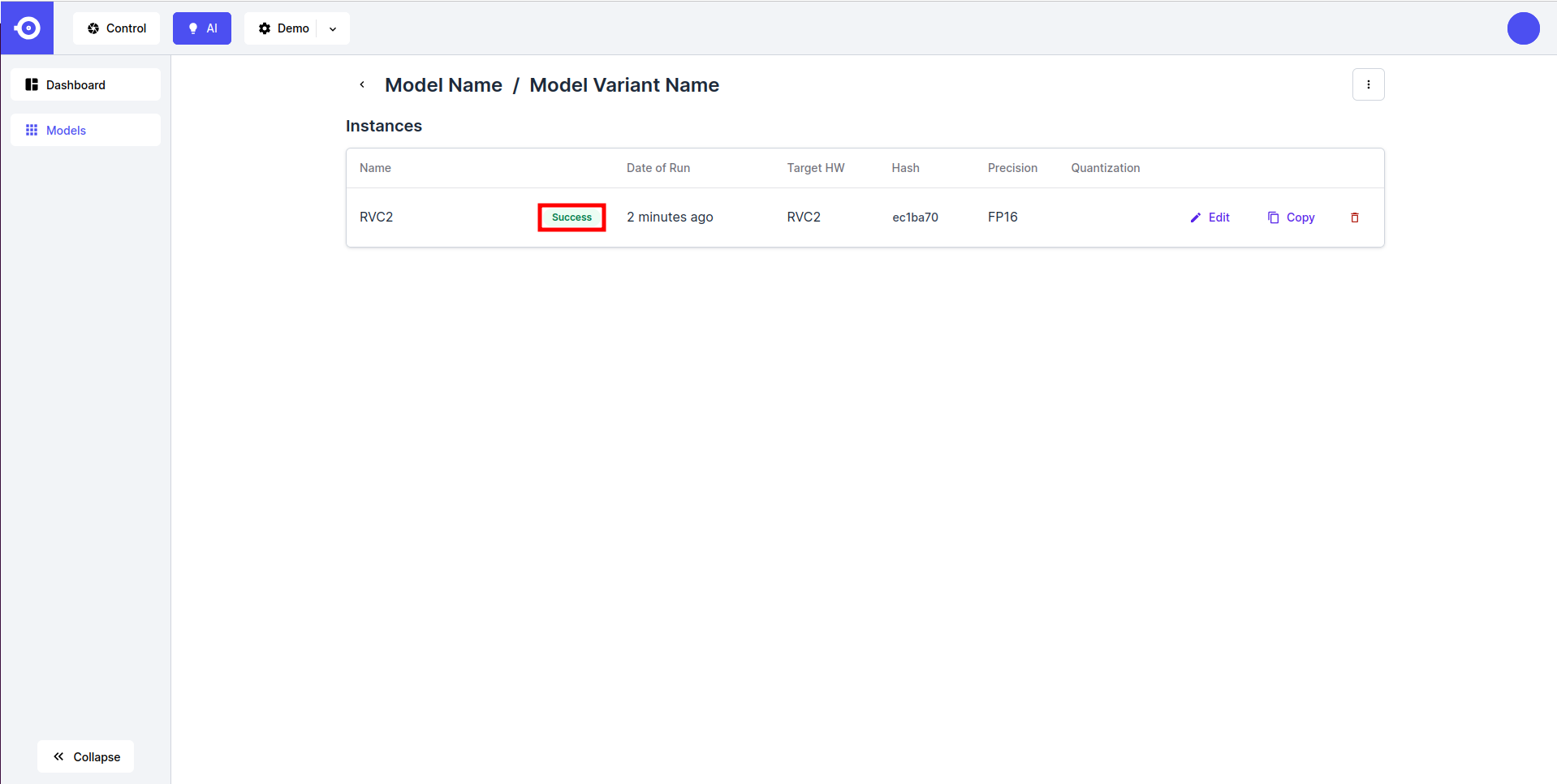
- 转换完成由 Success 状态标记. 现在可以通过 DepthAI API 下载或引用该模型(查看 Inference 指南).
故障排查
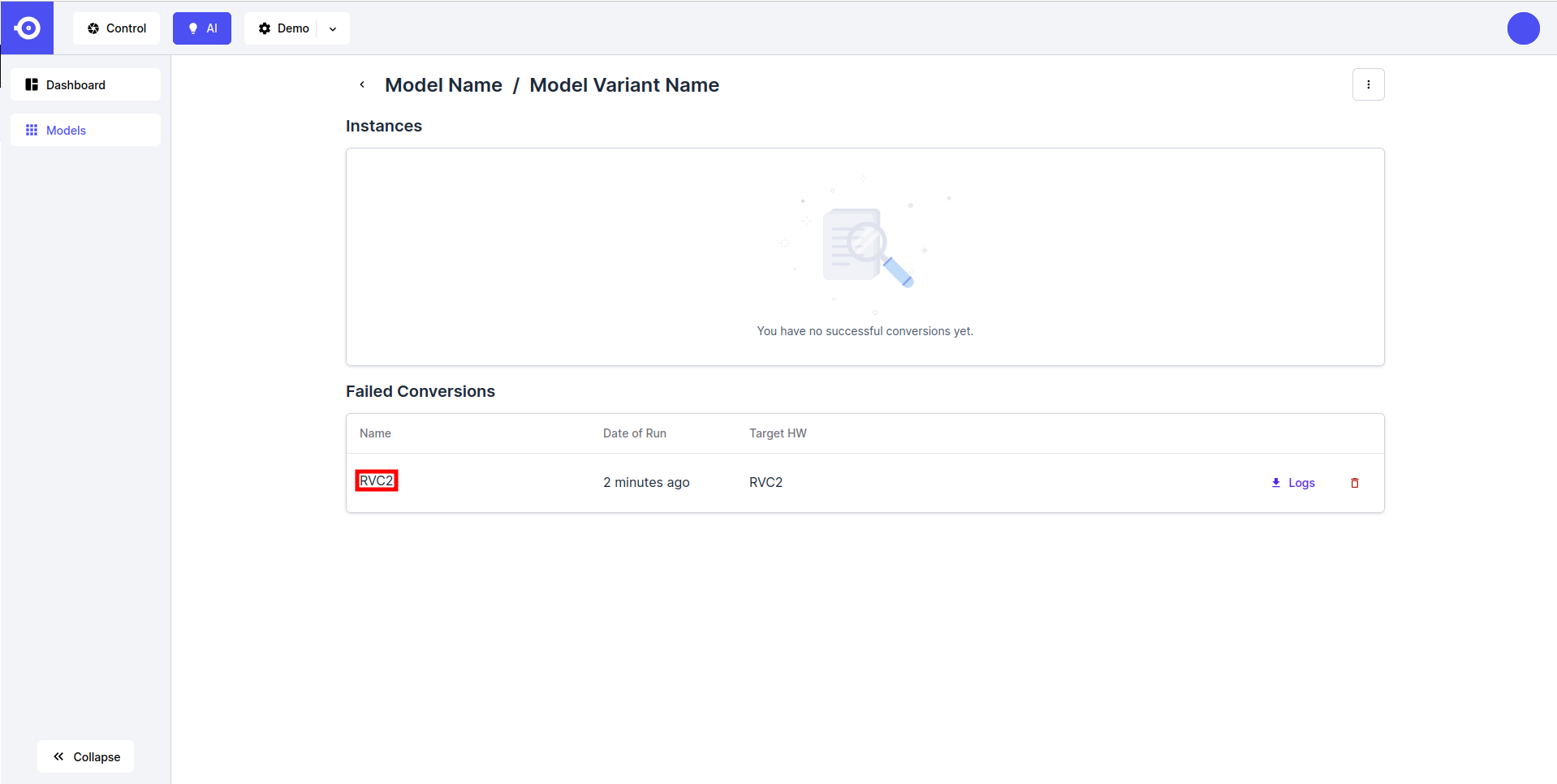
并非所有模型都可以针对所需平台进行转换. 您可以按如下方式检查失败的转换日志:- 在 Failed Conversions 部分找到"failed conversion job", 然后点击它的名称.
- 点击右上角的 Logs 按钮下载转化日志, 或通过滚动页面底部的 Conversion process logs 直接检查它们.
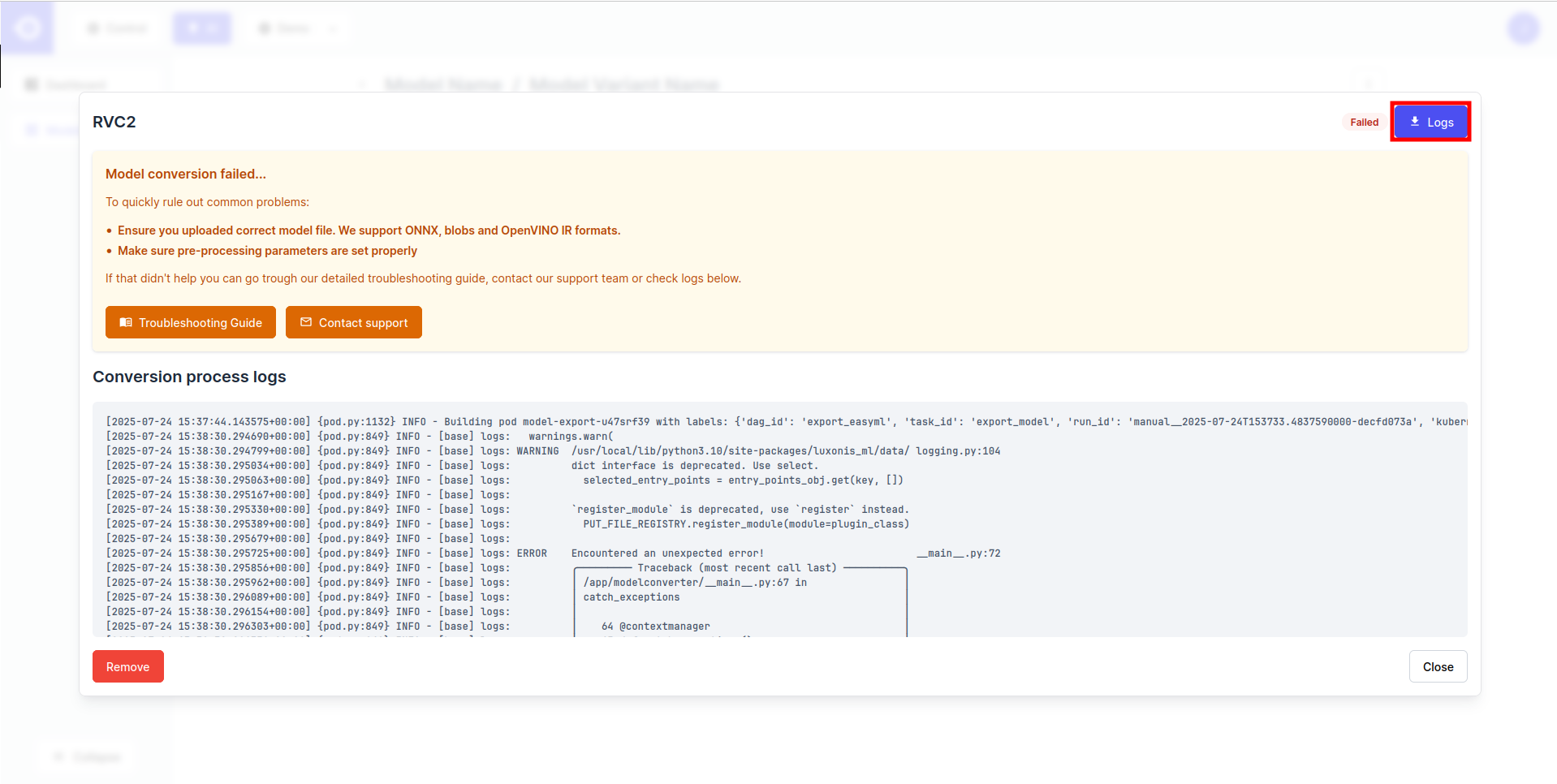
如果导出失败, 则需要对模型或使用的转换参数进行更正. 更多有关信息, 请参阅 Conversion Troubleshooting 页面.